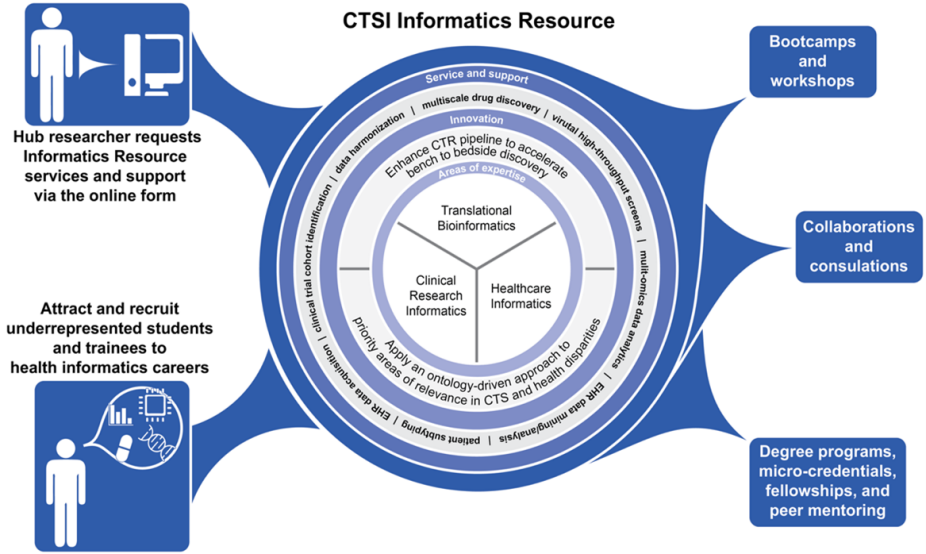
Services


The Informatics Core enables researchers to incorporate informatics and data science in their research. We provide support, service, and guidance to hub researchers in the use of technologies, spanning informatics and data science. Hub researchers seeking support can submit a service request at the link below.
Our team will contact a faculty member in any of Informatics Resource units with expertise to best aid the researcher. Our service offerings include:
Multiscale drug discovery
We can leverage the CANDO (Computational Analysis of Novel Drug Opportunities) platform enhanced with pathway and cellular scale signatures, integrated heterogeneous multi-omics data, and machine and deep learning architectures to predict new uses for existing drugs (drug repurposing) or create novel compounds with optimal therapeutic and safety profiles (drug design).
Protein structure prediction
We leverage cutting-edge tools, e.g., AlphaFold2, for protein/macromolecular structure, function, and interaction modeling, simulation, and analysis.
Virtual high-throughput screening
We offer expert support in technologies such as CANDOCK, DiffDock, Autodock Vina, and other molecular docking software. We can execute single or multiple macromolecular target virtual screens with libraries of approved, investigational, and/or designed chemical entities, whichever suits the needs of the researcher.
Bioinformatic analysis
We offer heterogeneous multi-omics analytics for molecular measurements, identification of differential expression levels in samples, and association of mechanisms to clinically relevant CTR phenotypes.
EHR data mining/analysis
We will extract unstructured health information via NLP (e.g., ontological/terminological normalization) and uncover patterns of clinical outcomes enabling opportunities for mitigation.
Data harmonization
We facilitate interoperability and integration of multiple data sources and data types.
Ontology development and use
We provide coordination, infrastructure, and independent review for researchers employing ontologies in healthcare and biomedical sciences.
AI development and use
We can help researchers identify, build, train, and validate artificial intelligence models for a variety of prediction and classification needs within biomedical science. We can also integrate heterogeneous multiscale data for robust clinical predictive models.
Patient subtyping/clustering
We will aid researchers in identifying unique characteristics of disease etiology and treatment for specific subpopulations who are broadly representative of our community.
Clinical decision support tools
We can develop and evaluate clinical decision support tools for translational research to improve healthcare, including incorporating SDOH data. This includes backend and frontend support for optimal efficacy and usability.
EHR data acquisition
We can extract patient data that enables execution of retrospective studies to test clinical research hypotheses. This is only executed upon proper IRB approvals.
Virtual research environment
We will create and manage a fully equipped remote desktop to allow researchers a computational sandbox to conduct informatics-based research with high level security and HIPAA compliance.
Clinical trial cohort identification
We can identify patients who are candidates for a researcher’s clinical trials to enable more effective and targeted recruitment of individuals who are broadly representative of our community.
Biological target prediction
Using tools within our CANDO platform, we can identify macromolecular entities that are implicated in various diseases and phenotypes. Furthermore, we can computationally elucidate metabolic, regulatory, and signaling pathways to uncover disease etiology and develop interventions.